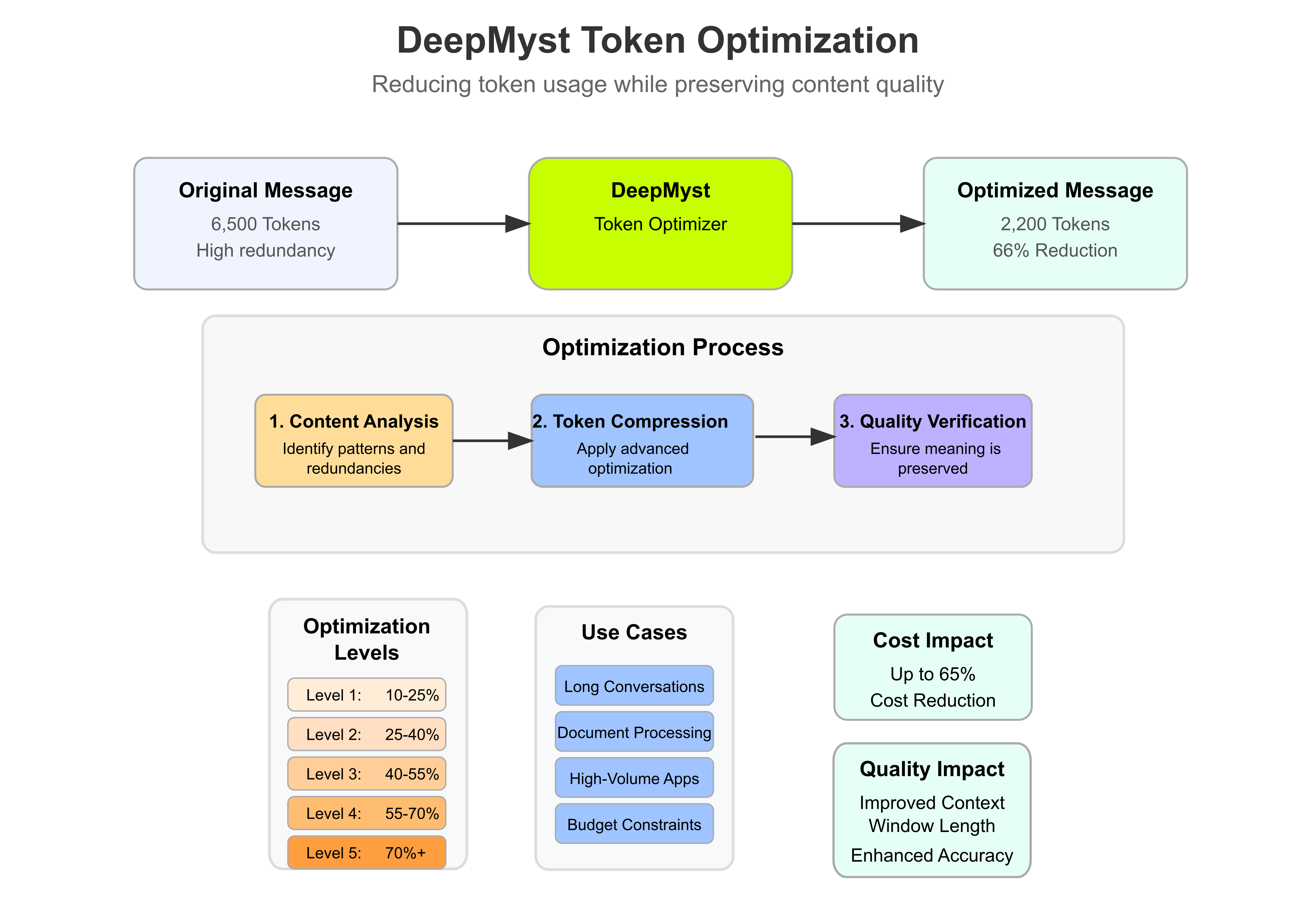
How Token Optimization Works
DeepMyst employs advanced compression techniques that:- Identify Redundancies: Our system analyzes message content to identify repeated phrases, patterns, and information
- Compress Content: Redundant content is intelligently compressed to reduce token count
- Preserve Context: Key information is maintained to ensure response quality isn’t compromised
- Restore Meaning: The optimization is transparent to the model, allowing it to generate high-quality responses
Benefits of Token Optimization
Cost Reduction
Reduce token usage by up to 75%, directly lowering your API costs
Preserved Quality
Maintain response quality while using fewer tokens
Longer Conversations
Fit more context within token limits for extended dialogues
Faster Processing
Reduced token counts can lead to faster processing times
Using Token Optimization
Enabling token optimization is as simple as adding the\-optimize flag to any model name in your API request:
Optimization Levels (Coming Soon)
DeepMyst automatically applies the appropriate level of optimization based on context, but you can also specify a particular optimization level:| Level | Description | Token Reduction | Use Case |
|---|---|---|---|
| 1 | Light optimization | 10-25% | When maximum preservation is critical |
| 2 | Balanced (Default) | 25-40% | General purpose optimization |
| 3 | Enhanced | 40-55% | Good balance of savings and quality |
| 4 | Aggressive | 55-70% | When cost savings are a priority |
| 5 | Maximum | 70-75%+ | When maximum savings are required |
Real-World Examples
Here are some real-world examples of token optimization in action:Example 1: Long-Form Content
Without Optimization:- Message size: 6,500 tokens
- Response size: 1,200 tokens
- Total tokens: 7,700
- Cost (at 0.077
- Optimized message size: 2,200 tokens (66% reduction)
- Response size: 1,200 tokens
- Total tokens: 3,400
- Cost: $0.034
- Savings: 56%
Example 2: Conversation History
Without Optimization:- 10-turn conversation: 12,000 tokens
- New response: 800 tokens
- Total tokens: 12,800
- Cost (at 0.128
- Optimized conversation: 3,600 tokens (70% reduction)
- New response: 800 tokens
- Total tokens: 4,400
- Cost: $0.044
- Savings: 65%
Best Practices
For maximum benefit from token optimization:- Use in multi-turn conversations: The benefits compound as conversation history grows
- Apply to information-dense queries: Content with repetition and patterns benefits most
- Balance with reasoning: Combine optimization with reasoning techniques for complex tasks
- Monitor quality: Watch for any impact on response quality and adjust optimization level if needed
- Preserve key instructions: Keep important system messages and instructions clear and precise
Optimization Analytics
The DeepMyst dashboard provides detailed analytics on your token optimization: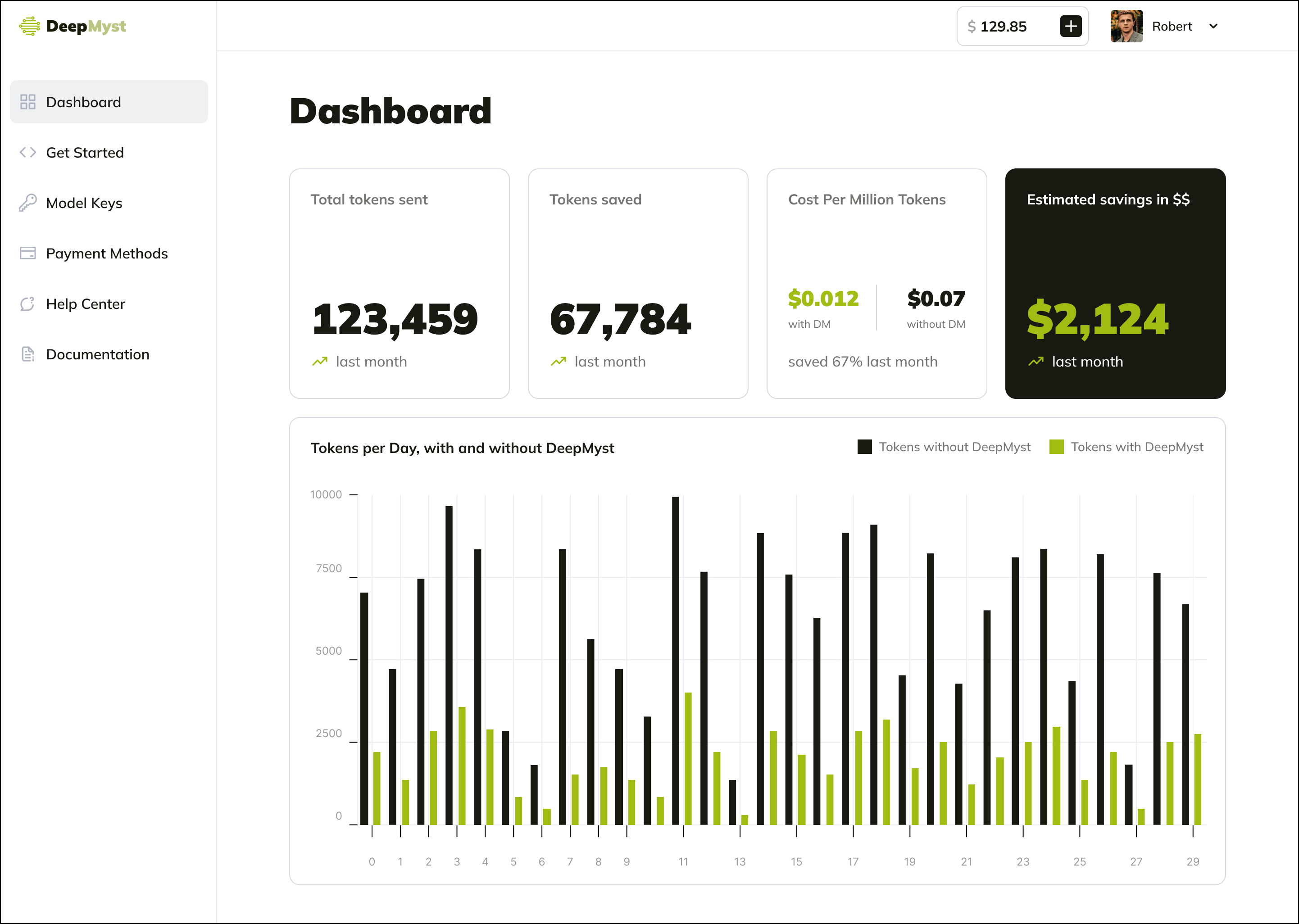
- Track total tokens saved
- Monitor cost reduction over time
- Compare optimization effectiveness across different models
- Identify opportunities for further optimization
When to Use Token Optimization
Token optimization is particularly valuable for:- Multi-turn conversations: As context grows, so do the savings
- Long-form content processing: When analyzing or generating extensive content
- High-volume applications: Applications making many API calls
- Fixed-budget projects: When working within strict cost constraints
- Context-window-limited scenarios: When you need to fit more content within token limits
Implementation Tips
To maximize the effectiveness of token optimization:- Start with balanced optimization: Begin with the default optimization level
- Test with your specific use cases: Different content types benefit differently
- Monitor quality metrics: Ensure optimization doesn’t impact critical outputs
- Combine with other DeepMyst features: Use alongside reasoning or routing for even better results
- Apply selectively: Use optimization where it makes the most sense for your workload